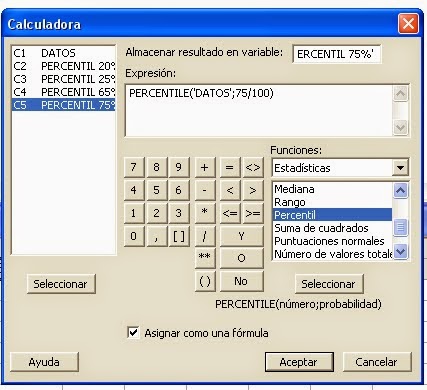
"RANGO"
La Estadística Descriptiva se denomina rango estadístico (R) o recorrido estadístico al intervalo entre el valor máximo y el
valor mínimo; por ello, comparte unidades con los datos. Permite obtener una idea de la dispersión de los datos, cuanto mayor
es el rango, más dispersos están los datos de un conjunto.
Por ejemplo, para una serie de datos de carácter cuantitativo, como lo es
la estatura medida en centímetros, tendríamos:

Es posible ordenar los datos como sigue:

Donde la notación x(i) indica
que se trata del elemento i-ésimo
de la serie de datos. De este modo, el rango sería la diferencia entre el valor
máximo (k) y el mínimo; o, lo
que es lo mismo:


En nuestro ejemplo,
con cinco valores, nos da que R =
185-155 = 30.
"RANGO INTERCUARTIL"
El rango intercuartílico IQR (o rango intercuartil) es una
estimación estadística de la dispersión de una distribución de datos. Consiste
en la diferencia entre el tercer y
el primer cuartil. Mediante esta medida se
eliminan los valores extremadamente alejados. El rango intercuartílico es
altamente recomendable cuando la medida de tendencia central utilizada es
la mediana (ya que este
estadístico es insensible a posibles irregularidades en los extremos).

Con el IQR podremos
elaborar los diagramas de caja, que
es un instrumento muy visual para evaluar la dispersión de una distribución.
Ejemplo:
Sea un conjunto ordenado de las edades
de los veinte sujetos (N=20) de un club.

Para calcular el rango intercuartílico, tendremos que calcular el
primer y el tercer cuartil (Q1 y Q3).
Ø Primer cuartil :
El primer cuartil será el sujeto (N+1)/4=21/4=5,25. Como
es decimal, será un número entre el X5=28 y X6=29.

El número decimal es el 5,25, por lo
que i=5 y d=0,25. El cuartil
1 es:
Ø Tercer cuartil :
El tercer cuartil es el sujeto 3(N+1)/4=63/4=15,75. Como
el número es decimal, el cuartil estará entre X15=52 y X16=53.

El número decimal es el 15,75, por lo
que i=15 y d=0,75. El cuartil
3 es:
Ø Rango intercuartílico :
Una
vez hemos calculado en primer y tercer cuartil, ya podemos calcular el rango intercuartílico.
“COEFICIENTE
DE VARIACION”
El coeficiente de variación es la relación entre la desviación
típica de una muestra y su media.

El coeficiente de variación se suele expresar en porcentajes:

El coeficiente de variación permite comparar las dispersiones de dos distribuciones distintas,
siempre que sus medias sean positivas.
Se calcula
para cada una de las distribuciones y los valores que se obtienen se comparan
entre sí.
La mayor
dispersión corresponderá
al valor del coeficiente de variación mayor.
Una distribución tiene x = 140 y σ = 28.28 y otra x =
150 y σ = 24. ¿Cuál de las dos presenta mayor dispersión?


La primera distribución presenta mayor dispersión.
El Coeficiente de variación (CV)
es una medida de la dispersión relativa de un conjunto de datos, que se obtiene
dividiendo la desviación estándar del conjunto entre su media aritmética y se
expresa generalmente en términos porcentuales.
Métodos de cálculo :
3.1)
Para una población se
emplea la siguiente fórmula:

3.2)
Para una muestra se
emplea la siguiente fórmula:

“PUNTO
Z”
Permite conocer que tan lejos de la
media se encuentra un valor determinado a partir de la media y la desviación
estándar. El punto Z sirve para hallar el área bajo la curva de la campana de
Gauss .

Un puntaje Z lo
que hace es decirnos a cuántas unidades de desviación estándar del promedio
está un puntaje determinado, o sea, no contamos en cantidad de puntos, sino en
cantidades de desviaciones estándar. Para utilizar el puntaje Z requerimos que
la distribución sea normal y Conocer el promedio y la desviación estándar de
los puntajes.




“TEOREMA
DE CHEBYSHEV”
Permite determinar que proporción
de los valores que se tienen en los datos deben estar dentro un determinado
número de desviaciones estándar de la media.
Para cualquier conjunto de datos (de una población o
una muestra) y cualquier constante k mayor que 1, el porcentaje de los datos
que debe caer dentro de k-veces la desviación típica de cualquier lado de
la media es:

De por lo menos:
El teorema de Chebyshev se aplica a cualquier
tipo de datos, pero sólo nos indica “por lo menos que porcentaje” debe caer
entre ciertos límites. Pero para casi todos los datos, el porcentaje real de
datos que cae entre esos límites es bastante mayor que el
que especifica el teorema de Chebyshev.
Para las
distribuciones que tienen forma de campana puede hacerse una aseveración más
fuerte:
(1) alrededor del 68% de los valores caerán
dentro de una desviación típica de la media esto es:

Entre:
(2) aproximadamente el 95% de los valores caerán
dentro de dos desviaciones típicas de la media, esto es:

(3) aproximadamente el 99,7% de los valores
caerán dentro de dos desviaciones típicas de la media, esto es:

Basándonos en el teorema de Chebyshev con k=2
¿Qué podemos decir del tamaño de nuestro error, si vamos a usar la media de una
muestra aleatoria de tamaño n=64 para estimar la media de una población infinita con =20.
Sustituyendo n=64 y =20 en la fórmula apropiada para el error estándar
:

De la media, obtenemos que :
y por el teorema de Chebyshev podemos afirmar que como
mínimo 1 - 1/22 = 0,75 que el error será menor que k· x = 2·2,5= 5.
Es decir que tenemos una garantía de que en el
75% de los casos la media de la población estará entre la media
calculada ±5 .
Pero esto no es suficiente, cuando la probabilidad
real de este caso puede estar entre 0,98 y el 0,999.

"REGLA EMPIRICA"
Es
posible que dos conjuntos de datos distintos tengan el mismo rango pero
difieran
considerablemente
en el grado de variación de los datos. En consecuencia, el rango es
una
medida relativamente insensible de la variación de los datos. La varianza tiene
importancia
teórica, pero es difícil de interpretar porque las unidades de medición de
la
variable de interés están elevadas al cuadrado. En cambio, las unidades de
medición
de
la desviación estándar son las unidades de la variable. Si la desviación
estándar se
combina
con la media del conjunto de datos, resulta fácil interpretarla.
Si
un conjunto de datos tiene una distribución aproximadamente simétrica se pueden
utilizar
las siguientes reglas prácticas para describir el conjunto de datos:
- Aproximadamente el 68 % de las observaciones quedan a una desviación estándar de su media (es decir, dentro del intervalo)

·
Aproximadamente el 95 % de las observaciones quedan a dos
desviaciones estándar

·
Casi todas las observaciones quedan a tres desviaciones
estándar de su media (es

La
regla empírica es el resultado de la experiencia práctica de investigadores en
muchas
disciplinas, que han observado muy diferentes tipos de conjuntos de datos de
la vida real.